
Nginx is a popular web server that keeps track of all HTTP requests that come in. These log files can tell you a lot about web traffic, like how many people visit, what pages they look at, and what response codes the server gives. In this blog post, we’ll look at how to use Python to parse Nginx log files.
Table of Contents
The script
import argparse
import csv
import re
import glob
from datetime import datetime
import os
import gzip
# Define a regular expression pattern to match a line in an nginx log file
line_format = re.compile(r'(\S+) - - \[(.*?)\] "(.*?)" (\d+) (\d+) "(.*?)" "(.*?)"')
# Define a function to format bytes as a string with a unit
def format_bytes(bytes):
for unit in ['B', 'KB', 'MB', 'GB', 'TB']:
if bytes < 1024.0:
return f"{bytes:.2f} {unit}"
bytes /= 1024.0
# Define a function to process nginx log files
def process_logs(log_path, output_file):
# Check if the log_path is a directory or a file, and get a list of files to process
if os.path.isdir(log_path):
files = glob.glob(log_path + "/*.gz") + glob.glob(log_path + "/*.log")
elif os.path.isfile(log_path):
files = [log_path]
else:
print("Invalid log path")
return
# Define some variables to store summary statistics
ip_counts = {}
status_counts = {}
status403_ips = {}
referrer_counts = {}
bytes_sent_total = 0
# Open the output file and write the header row
with open(output_file, 'w', newline='') as csvfile:
writer = csv.writer(csvfile)
writer.writerow(["IP", "Timestamp", "Method", "URL", "Status", "Bytes Sent", "Referrer", "User Agent"])
# Loop over each file to process
for filename in files:
# Check if the file is gzipped or not, and open it accordingly
if filename.endswith('.gz'):
open_fn = gzip.open
else:
open_fn = open
# Open the file and loop over each line
with open_fn(filename, 'rt', encoding='utf-8') as file:
for line in file:
# Match the line against the regular expression pattern
match = line_format.match(line.strip())
# If there is a match, extract the relevant fields and write them to the output file
if match:
ip, date_str, request, status, bytes_sent, referrer, user_agent = match.groups()
dt = datetime.strptime(date_str, '%d/%b/%Y:%H:%M:%S %z')
try:
method, url = request.split()[0], " ".join(request.split()[1:])
except IndexError:
method, url = request, ''
writer.writerow([ip, dt, method, url, status, bytes_sent, referrer, user_agent])
# Update summary statistics
ip_counts[ip] = ip_counts.get(ip, 0) + 1
status_counts[status] = status_counts.get(status, 0) + 1
bytes_sent_total += int(bytes_sent)
if status == '403':
status403_ips[ip] = status403_ips.get(ip, 0) + 1
referrer_counts[referrer] = referrer_counts.get(referrer, 0) + 1
# Print summary stats
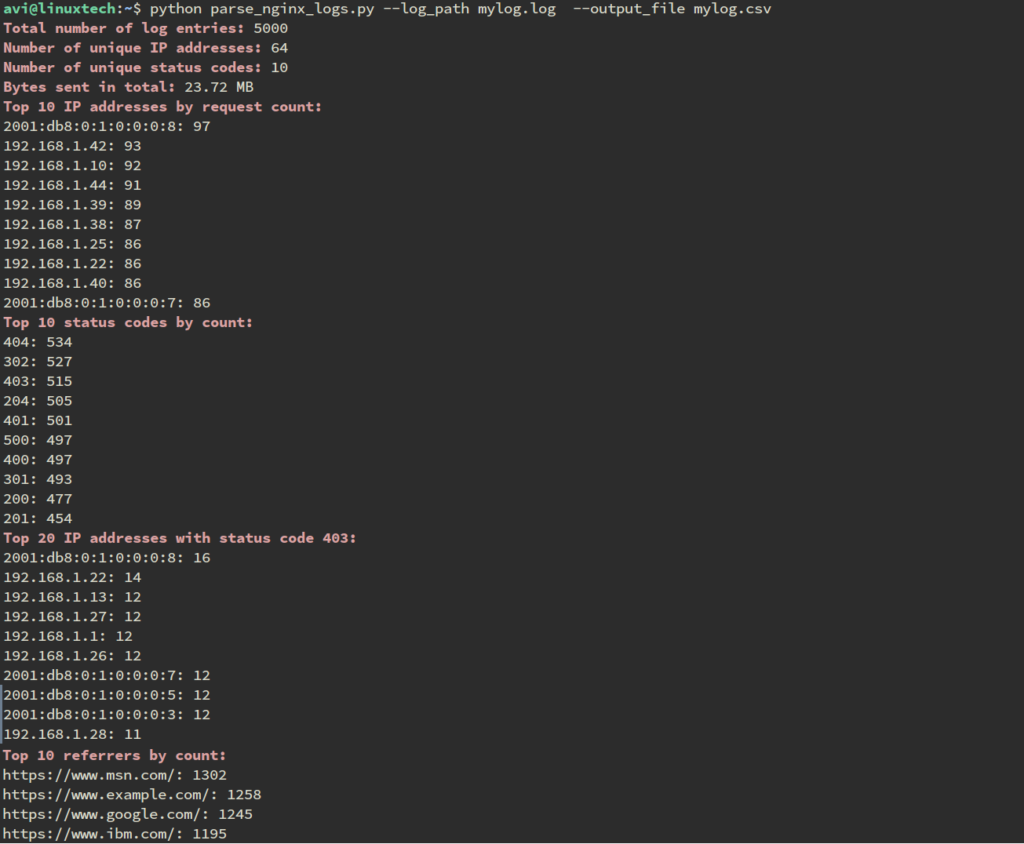
print("\033[1m\033[91mTotal number of log entries:\033[0m", sum(ip_counts.values()))
print("\033[1m\033[91mNumber of unique IP addresses:\033[0m", len(ip_counts))
print("\033[1m\033[91mNumber of unique status codes:\033[0m", len(status_counts))
print("\033[1m\033[91mBytes sent in total:\033[0m", format_bytes(bytes_sent_total))
print("\033[1m\033[91mTop 10 IP addresses by request count:\033[0m")
for ip, count in sorted(ip_counts.items(), key=lambda x: x[1], reverse=True)[:10]:
print(f"{ip}: {count}")
print("\033[1m\033[91mTop 10 status codes by count:\033[0m")
for status, count in sorted(status_counts.items(), key=lambda x: x[1], reverse=True)[:10]:
print(f"{status}: {count}")
print("\033[1m\033[91mTop 20 IP addresses with status code 403:\033[0m")
for ip, count in sorted(status403_ips.items(), key=lambda x: x[1], reverse=True)[:10]:
print(f"{ip}: {count}")
print("\033[1m\033[91mTop 10 referrers by count:\033[0m")
for referrer, count in sorted(referrer_counts.items(), key=lambda x: x[1], reverse=True)[:10]:
print(f"{referrer}: {count}")
if __name__ == '__main__':
parser = argparse.ArgumentParser(description='Process nginx log files.')
parser.add_argument('--log_path', metavar='LOG_PATH', type=str,
help='Path to the log file or directory')
parser.add_argument('--output_file', metavar='OUTPUT_FILE', type=str,
help='Path to the output CSV file')
args = parser.parse_args()
process_logs(args.log_path, args.output_file)
Script Usage
The script takes two command-line arguments: --log_path, which specifies the path to the Nginx log file or directory, and --output_file, which specifies the path to the output CSV file. To run the script, open a terminal and navigate to the directory containing the script. Then, run the following command:
python parse_nginx_logs.py --log_path /path/to/logs --output_file /path/to/output.csvReplace /path/to/logs with the path to the Nginx log file or directory, and /path/to/output.csv with the path where you want to save the output CSV file.
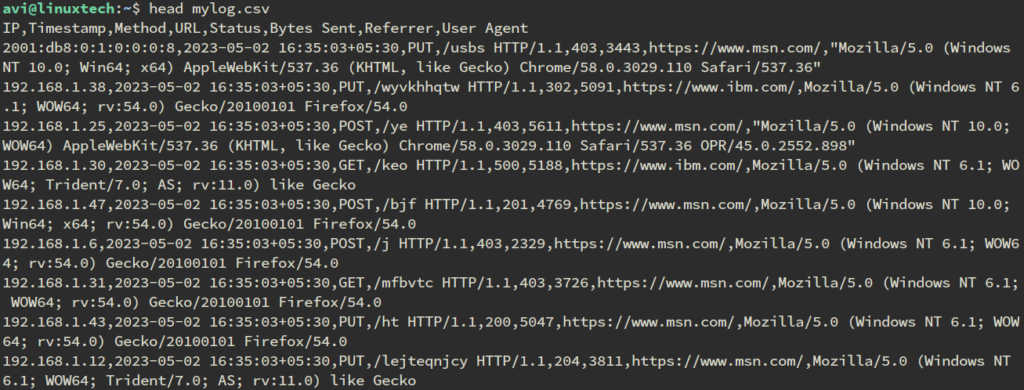
The output CSV file will contain the following columns:
- IP: The IP address of the client
- Timestamp: The date and time of the request
- Method: The HTTP method used for the request (e.g., GET, POST)
- URL: The URL requested
- Status: The HTTP status code returned by the server
- Bytes Sent: The number of bytes sent in the response
- Referrer: The referrer URL, if available
- User Agent: The user agent string of the client, if available
How The Code Works
The script begins by importing the necessary modules, including argparse for command-line argument parsing, csv for writing the output to a CSV file, re for defining a regular expression pattern to match lines in the log file, glob for finding log files in a directory, datetime for parsing the timestamp, and os and gzip for handling compressed log files.
The script defines a regular expression pattern line_format that matches a line in an Nginx log file. The pattern matches the following fields:
- IP address
- Timestamp
- HTTP request
- HTTP status code
- number of bytes sent in the response
- Referrer URL
- User agent string
The script defines a function format_bytes that formats a number of bytes as a string with a unit (e.g., "1.23 MB").
The main function of the script is process_logs, it takes a log file path and an output file path as input. The function first checks if the log path is a directory or a file and creates a list of files to process.
The function then defines some variables to store summary statistics, including ip_counts for counting the number of requests from each IP address, status_counts for counting the number of requests with each status code, status403_ips for counting the number of requests with a 403 status code from each IP address, referrer_counts for counting the number of requests from each referrer URL, and bytes_sent_total for keeping track of the total number of bytes sent in the response.
The function opens the output file and writes a header row to the CSV file. The function then loops over each log file to process. For each file, the function checks if the file is compressed and opens it accordingly. The function then loops over each line in the file, matches the line against the regular expression pattern, and extracts the relevant fields. The function then writes the fields to the output CSV file.
Finally, the function prints summary statistics, such as the total number of log entries, the number of unique IP addresses, and the top 10 IP addresses by request count.
Conclusion
Parsing Nginx log files can provide valuable insights into web traffic and server performance. In this blog post, we explored how to parse Nginx log files using Python. We wrote a script that extracts relevant fields from the log files, updates summary statistics, and writes the results to an output CSV file.
Link to Github:
https://github.com/linuxinsights/Parsing-Nginx-Log-Files
Got any queries or feedback? Feel free to drop a comment below!
Keep on writing, great job!